Comment on OpenAI releases o1, its first model with ‘reasoning’ abilities
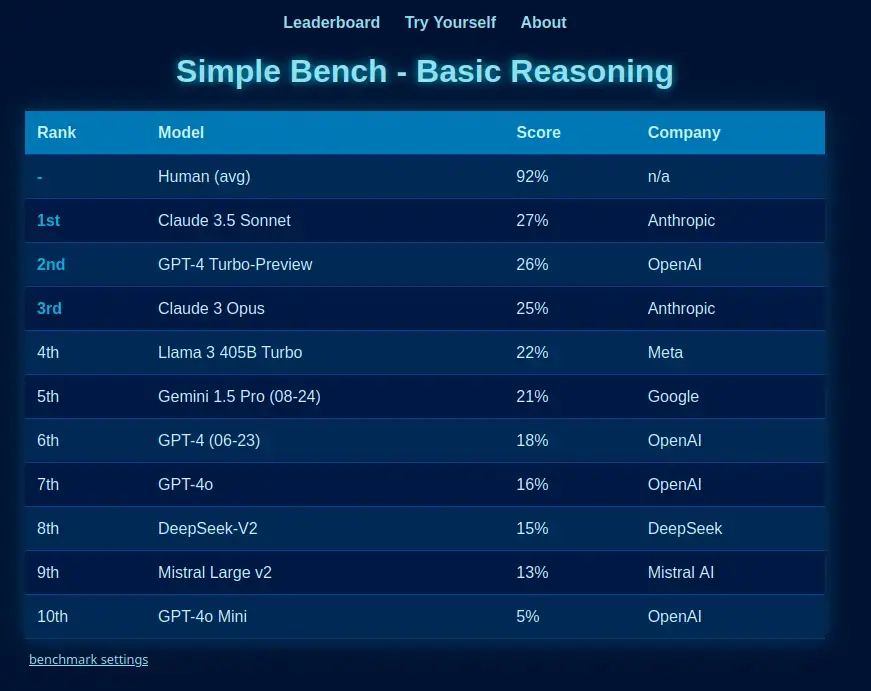
Martineski@lemmy.dbzer0.com 1 year agosimple-bench.com/index.html I was referring to this benchmark specifically because the point of it is to benchmark the actual reasoning capabilities of LLMs:
Simple bench is the only reasoning benchmark written in natural language at which English-speaking humans (and yes, even ‘smart highschoolers’) can score 90%+, while frontier LLMs get less than 50%. It is an encapsulation of the reasoning deficit found in AI like ChatGPT.
These questions are fully private, preventing contamination, and have been vetted by PhDs from multiple domains, as well as the author - Philip, from AI Explained - who first exposed the numerous errors in the MMLU (Aug 2023). This was celebrated by, among others Andrej Karpathy.
{kind=link}