Martineski
@Martineski@lemmy.dbzer0.com
- Comment on Valve open source the Steam Machine e-ink screen so you can make your own 4 weeks ago:
Hehe
- Comment on Valve open source the Steam Machine e-ink screen so you can make your own 4 weeks ago:
Well, technically eink displays don’t have backlight but frontlight.
- Comment on YouTube now lets you turn off Shorts 3 months ago:
I feel you. Learned about it just recently but revanced still works for me so I’m not going to bother changing anything right now.
- Comment on YouTube now lets you turn off Shorts 3 months ago:
Heard it got discontinued by devs leaving over POS repo owner and that “Morphe” is it’s successor with the devs moving there instead.
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
I don’t understand why you are bringing other platforms up. This isn’t sport. Just because I’m calling out valve doesn’t mean I side with other platforms (teams) and think that they are better and need to win…
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
It’s not just about the children buddy. Adults are veulnerable too. There’s no need to throw them off the cliff just because they passed that special age mark. Your solution about requiring id check to prevent children from gambling wouldn’t do anything about adults because the issue is far more fundamental and about how the system is structured not how you enter it. Also it’s not about corporations doing parent’s job but about wanting something as simple as corporations not exploiting people including in big part children. You’re paiting this thread like valve is good and we are asking valve to do more good by doing job of the parents while in reality we want valve to stop doing evil that valve does. And yet you will insist that you are not defending a corporation. The delusion is crazy.
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
By that logic valve would be justified with even 95% cut if network efect was even stronger. That’s stupid logic that only thinks in terms of working with what you have. Valve already takes a cut and not a hard value. It’s in their very business to increase sales and they shouldn’t be additionally rewarded for such because by increased sales they already get the money.
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
Like taking a massive cut because they have network effect to their advantage isn’t. I’m mocking them because they mock people pointing out issues with the platform without anything in this thread prompting them to do that.
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
They were also the ones to bring out the 30% cut mocking the people talking about it in general and when I called them out they doubled down saying that sharing an opinion is not defending a corporation. Lmao
I see so many bad takes from them in this thread and it’s wild to see people upvote them. I thought the users here would know better about tech instead of getting parasocial with a corporation and thinking it can’t do bad…
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
And I was talking about literal casinos running on steam and not the exploitative games in there. There’s absolutely no reason for steam virtual market (don’t remember the name) to exist (besides it making valve money) and they could crack down on casinos easily but again, that makes them money. Also steam popularised lootboxes and they have this dumb case + key psychological trick in cs to drive more purchases. As for the 30% cut, the indie devs already have it rough. Developing a game takes a lot of effort and time. Taking 30% cut while publishers take another cut on top makes it hard for indies to sustain themselves and so they often close down. Not to mention the insanity of steam actually lowering the cut for really big studios (the more you earn the lower the cut) to keep them on the platform when corporations will do just fine and the indies need the money the most.
- Comment on Steam is adding support to show estimated FPS for your hardware before buying a game 3 months ago:
I agree. We need more kids being exposed to gambling. Steam earning money from ruining children is very important for those neat features. :3 Steam FTW. Amirite g*mers? <333
For real though. This is just long term business strategy. They are not your friend. They can do things things that are good and ghings that are very bad. Stop definding big corporation that doesn’t know or care about your existence. I can’t even discribe how sad it is to be a person that needs to get defensive about a corporation because their service is alright for the most part.
- Comment on Linux smashes past 5% on the Steam Survey for the first time (note: percentage is questionable) 3 months ago:
OBLIBERATED
- Comment on OpenAI releases o1, its first model with ‘reasoning’ abilities 1 year ago:
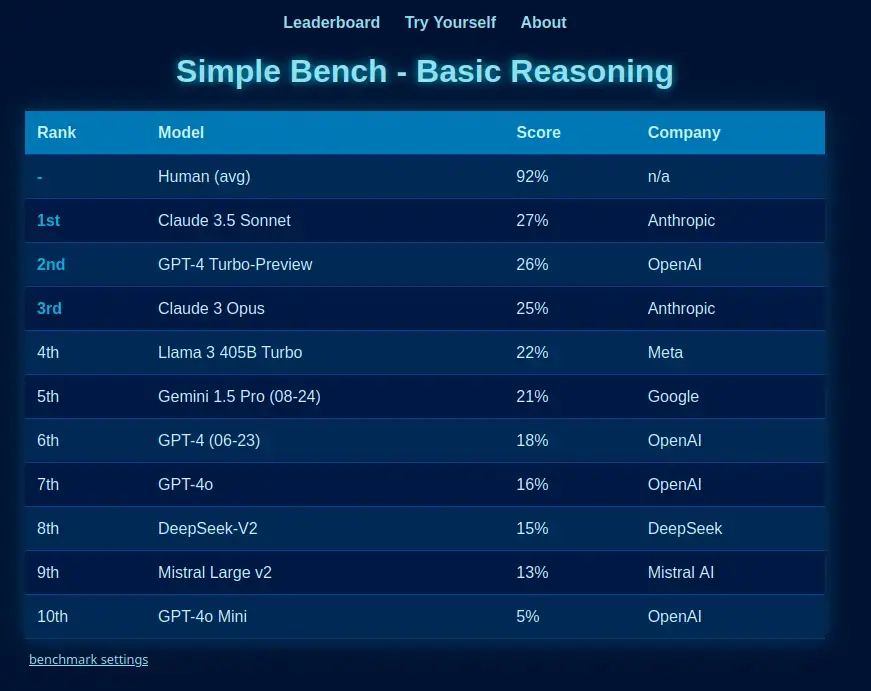
simple-bench.com/index.html I was referring to this benchmark specifically because the point of it is to benchmark the actual reasoning capabilities of LLMs:
Simple bench is the only reasoning benchmark written in natural language at which English-speaking humans (and yes, even ‘smart highschoolers’) can score 90%+, while frontier LLMs get less than 50%. It is an encapsulation of the reasoning deficit found in AI like ChatGPT.
These questions are fully private, preventing contamination, and have been vetted by PhDs from multiple domains, as well as the author - Philip, from AI Explained - who first exposed the numerous errors in the MMLU (Aug 2023). This was celebrated by, among others Andrej Karpathy.
- Comment on OpenAI releases o1, its first model with ‘reasoning’ abilities 1 year ago:
I’m curious how it will do on the private benchmark that ai explained made. I think it was called simple bench?
{kind=link}